Cloud Engineering &
Containerisierung
Entwicklung von hochverfügbaren, sicheren
Container-Plattformen auf Basis von Kubernetes
Kubernetes-Plattform
Für die Integration, Modernisierung und Weiterentwicklung bestehender Architekturen setzen wir auf einen Multi-Cluster-Ansatz auf Basis von Kubernetes, Prometheus und Istio.
Einerseits verringert die standardisierte Containerorchestrierung einer Kubernetes-Plattform die direkten Abhängigkeiten zwischen Workload und Infrastruktur – das Gesamtsystem wird robuster und schneller. Andererseits erhöht sich das Innovationstempo, weil der Fokus mehr auf der eigentlichen „Entwicklung“ liegen kann.
System-Sicherheit
Die System-Sicherheit wird zum zentralen Aspekt jeder IT-Organisation, weil sich die Bedrohungslage für staatliche Einrichtungen und Unternehmen im Bereich der kritischen Infrastruktur zukünftig noch weiter verschärfen wird.
Wir glauben, dass IT-Sicherheit am besten durch eine open source basierte Architektur erreichen werden kann. Denn open source kann sehr schneller auf konkrete Bedrohungen reagieren.
Kosten / No Vendor-Log-In
Im Gegensatz zu proprietären Herstellersystemen „kostet“ eine Kubernetes-Plattform keine Lizenzgebühren. Entwicklungsprojekte können hierdurch sehr schnell und einfach realisiert werden. Ebenfalls bestehen keine Hürden (und Zeitverluste), wenn zusätzliche Systeme und Kompetenten in die Plattform integriert werden sollen.
Flexibilität und Skalierung
Unser Kubernetes-basierter Containeransatz ist vollständig plattformagnostisch. Ob „on prem“ oder „cloud-based“ bei einem der bekannten Hyperscaler – unser Plattform-Ansatz ist hochflexibel und beliebig skalierbar. Wenn notwendig mit duzenden von Clustern, hunderten von Cores und für tausende Entwickler.
Use Case
Bundesbehörde - Höhere Sicherheit und Unabhängigkeit durch Nutzung von Kubernetes
Ablösung einer monolithischen System-Architektur durch Nutzung von Microservices auf der Basis von Kubernetes
Situation:
Migration von internen Anwendungen auf eine neue Intranetplattform, mit dem Fokus auf open source Software und einer Cloud Native Architektur.
Was wir tun
Wir helfen Ihnen dabei, Ihre Kubernetes-Plattform aufzubauen
Als zertifizierter Partner von SUSE unterstützen wir Sie bei der Entwicklung einer hochverfügbaren, sicheren Container-Plattform. Dabei basiert unsere Herangehensweise auf einem agilen Framework (SCRUM) und einem übergreifenden Plattform-Team.

1. Ramp-up
- Skizzierung einer ersten Struktur der Containerplattform
- Berücksichtigung von äußeren Faktoren und Gegebenheiten
- Definition des Projektteams aus internen und externen Entwicklern (max. Informationsaustausch)
2. Architektur
- Konzeption der Architektur des Gesamtsystems (Plattform, Netzwerk, Umsysteme)
- Entwicklung und Test der Architektur, i.S. eines Proof-of-Concepts (PoC)
- Berücksichtigung aller Sicherheits-mechanismen (Secure by Design)
3. Sizing
- Schätzung des zukünftigen Bedarfs an Plattform (Nodes, Storage, Managementsystem) und der Umsysteme (Versionsverwaltung, CI/CD, Image-Registries, Loadbalancer etc.)
- Grundlage: Bisherige Ressourcennutzung bzw. Schätzungen der Entwicklerteams (bei einer Neuentwicklung)
4. MVP-Entwicklung
- Zunächst Ausbau des PoC zu einem MVP
- Danach wird der MVP iterativ verbessert, getestet und erweitert
- Hierdurch können nachträgliche Anpassungen von einzelnen Plattformkomponenten erreicht werden
- Laufende (agile) Integration verschiedener Umsysteme (z.B. Image-Registries, CI/CD und Secret Pipelines) schon in den ersten Entwicklungsphasen
5. Sicherheit
- Härtung der Plattform-Konfiguration durch Benchmark-Scans (z.B. CIS) und durch regelmäßige Prüfungen
- Zertifikat-System, für die Einbindung von externen Komponenten
- Einrichtung von Rechteverwaltung (z.B. RBAC) und Segmentierung (z.B. Networkpolicies)
- Integration von zusätzlichen Security-Tools, wie z.B. Transportverschlüsselung (ServiceMesh), Anomalie-Detektion, Secret-Management (z.B. HashiCorp Vault) usw.
6. GoLive
- Entscheidend ist die Akzeptanz bei den Entwicklern
- Bei Plattformen, die kompliziert, fehleranfällig oder nicht performant genug sind, ist der zeitliche Ablauf der Anwendungsmigrationen und Entwicklungen gefährdet
- Erfolgsentscheidend sind die Dokumentation, Einführungsworkshops/ Schulungen sowie bereitgestellte Templates und Tools (CI/CD Integration, GitOps)
- Eine automatisierte Qualitätssicherung und umfassende Observability runden den Produktivgang ab
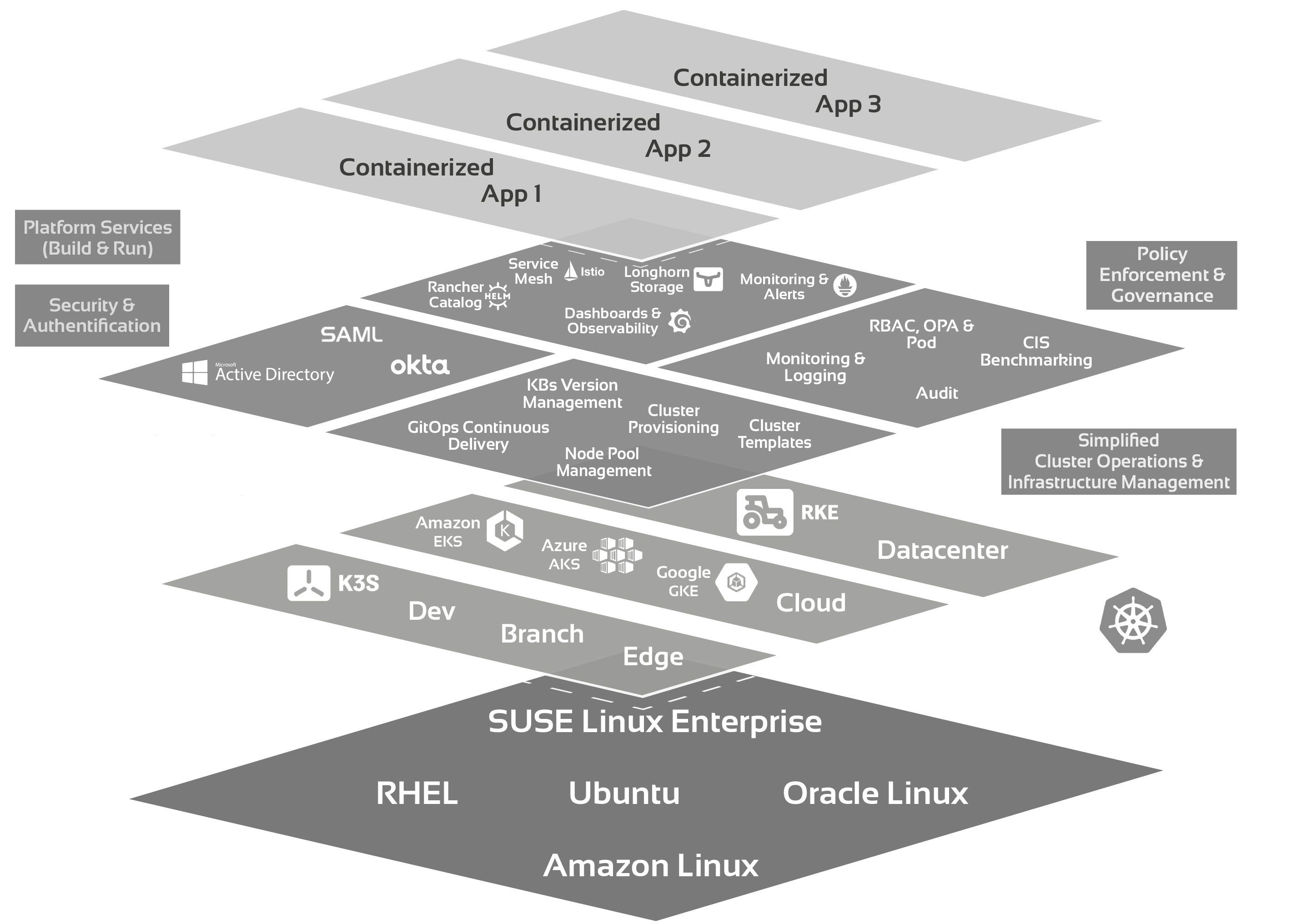
Unsere Basis mit RANCHER®
Wir verwenden Cloud Native für containerisierte, verteilte Systeme, die durch horizontale und vertikale Skalierbarkeit, Ausfallsicherheit und Selbstheilung die Möglichkeiten des Cloud Computings ausnutzen um das beste Benutzererlebnis zu liefern.
Unser Tool Stack baut dafür auf Kubernetes auf, ergänzt dieses aber durch bewährte Tools wie Istio, Prometheus und Grafana.
Da komplexe Systeme aus unserer Sicht aber übersichtlich und gut zu administrieren sein sollten, arbeiten wir schon seit 2019 mit SUSE RANCHER®, dem führenden Kubernetes Management System.
Secure by Design
Entsprechend der zunehmenden Bedrohungslage umfasst das novellierte IT-Sicherheitsgesetzes (NIS 2 Richtlinie der EU) nunmehr eine ganze Reihe von Wirtschaftszweigen, die zukünftig die hohen KRITIS-Sicherheitsanforderungen erfüllen müssen.
Um eine Kubernetes-Plattform abzusichern, setzen wir auf Secure by Design. Hierbei spielt das Service Mesh – die dritte Evolutionsstufe der Containerplattformen – eine zentrale Rolle. Zusammen mit Ingress- und Egress-Gateways (Bastion-Nodes) und Authentifizierungs-Proxies sind mit dem Service Mesh Zero-Trust-Ansätze, vollständige Kommunikationsverschlüsselung und Microsegmentierungen möglich.
Mit Istio kann die Verschlüsselung der Kommunikation über mTLS erreicht werden und gleichzeitig können auch viele weitere optionale Features für Authentifikation, Autorisierung und Ausfallsicherheit umgesetzt werden.
Hierdurch kann auch eine cloud-native Kubernetes-Plattform die Anforderungen des BSI und auch der BaFin (BAIT, MaRisk, und DORA) erfüllen.
Cloud Native Technologien -
unsere Grundlage
Wir nutzen die open source software der Cloud native computing foundation (CNCF), der Apache Foundation und großer Distributoren wie SUSE und Confluent.
Methoden
Open Source Entwicklung | Software Engineering | DevOps | DevSecOps | SCRUM | Cloud native Architekturen | Hybride Architekturen | Kappa-Architekturen
Hersteller
CNCF | SUSE | Apache | Linux | Rancher | Confluent | Imply | Pure Storage | snowflake | Google Cloud | AWS | Microsoft Azure
Software
Deep Dive
Wenn Sie mehr über das Team und unsere Projekte sowie die neuesten Entwicklungen in den Bereichen Kubernetes und Cloud Native Computing erfahren wollen, dann besuchen Sie uns doch einfach auf kubespectra.com

Cloud Engineering
heißt für uns:
Aufbau, Entwicklung und Betrieb einer cloud-nativen Kubernetes-Plattform auf bare metal, in Ihrer private Cloud, bei Google Cloud Services, AWS oder Azure.
Hier können wir auf umfassende Erfahrungen bei der Umsetzung plattformagnostischer Multi-Cluster-Architekturen in staatlichen Einrichtungen und bei Unternehmen im Bereich der kritischen Infrastruktur (Gesundheit und Finanzwirtschaft) zurückgreifen.
Daher wissen wir, dass es nicht nur um die Anforderungen an die neue Plattform geht, sondern dass auch das Zusammenspiel mit den bereits bestehenden System-Komponenten eine sehr große Bedeutung hat.
Hier begleiten wir Sie, bei der Migration und Verbesserung Ihrer Enterprise Software (Security by Design) sowie bei der Einführung von DevOps-Ansätzen und der Automatisierung.
Dr.-Ing. Harald Gerhards
Head of Cloud Engineering