
Verfasst von: Hendrik Becker, Senior IT-Consultant
Jeder ETL-Entwickler kennt das. Der Fachbereich stellt eine neue Anforderung an die Datenbewirtschaftung und man fragt sich: Wie setze ich das Ganze in DataStage um? Setze ich auf ein herkömmliches Jobdesign mit festen, hart kodierten Tabellenstrukturen? Oder bietet sich ggf. eine generische Lösung an, die ein flexibles Metahandling erlaubt und damit eine besonders smarte Umsetzung ermöglicht?
Bei mir persönlich stehen generische Ansätze hoch im Kurs – gerade, wenn es um die Entwicklung von wiederverwendbaren Komponenten wie etwa Shared Container oder universellen „Table Loader“ Prozessen geht. Auch wenn man am Anfang sicher etwas mehr Aufwand dafür betreiben muss, am Ende rentiert sich dieser- auch für den Kunden. Denn langfristig lassen sich durch den Einsatz generischer Komponenten Pflegeaufwände im ETL minimieren, und es kann eine Einheitlichkeit bei der Umsetzung sichergestellt werden.
Im Folgenden schreibe ich zunächst über das Grundlagen-Know-how, welches man sich als ETL-Entwickler im Vorfeld aneignen sollte.
In einem späteren Artikel werde ich dann über die Umsetzung von Shared Container anhand konkreter Beispiele aus der Praxis berichten.
Zu den Grundlagen gehören Konzepte wie Parametrisierung und die sog. Runtime Column Propagation (RCP) sowie der Einsatz spezieller Operatoren wie die Modify Stage und die Generic Stage.
Parametrisierung
Dieser Punkt bedarf eigentlich keiner großen Erläuterung. In jeder DataStage Grundlagenschulung wird auf den Nutzen von Umgebungsvariablen, Jobparametern und Parameter Sets hingewiesen. Aber leider erlebt man es in der Praxis häufig, dass von Parametrisierung nicht ausreichend Gebrauch gemacht wird. Dabei kommt es gerade im „generischen Kontext“ darauf an, das Laufzeitverhalten eines Jobs bzw. einer Komponente durch Parametrisierung von außen beeinflussen und somit flexibel an verschiedene Bedingungen anpassen zu können.
Runtime Column Propagation (RCP)
Unter RCP versteht man, dass DataStage eigenständig zur Laufzeit die erforderlichen Metadaten ermittelt. D.h. der Entwickler braucht im Job nicht mehr die gesamten Tabellendefinitionen angeben, sondern DataStage ermittelt diese selbst, z. B. aus dem Systemkatalog der Datenbank oder dem Descriptorfile des Datasets im orchestrate shell (osh). Im Job müssen dann nur noch die Spalten explizit angegeben werden, mit denen man aktiv arbeiten möchte, z. B. um einen Join durchzuführen.
Um RCP ein- bzw. auszuschalten, gibt es 3 Möglichkeiten:
(1) Projektweit über den DataStage Administrator
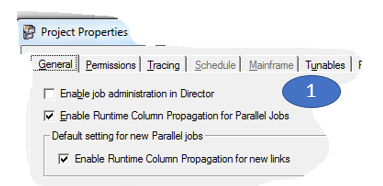
(2) Lokal in den Jobproperties
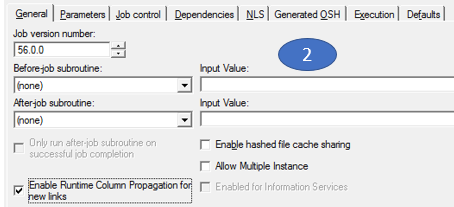
(3) Im Output-Tab einer Stage (Columns)
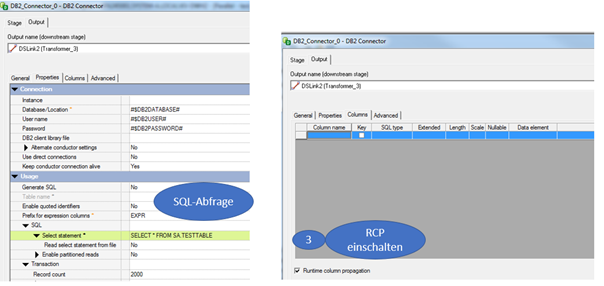
Das Beispiel hier oben zeigt den wohl einfachsten Copy-Job, den man sich vorstellen kann.
Modify Stage
Diese Stage wird überwiegend im Kontext RCP eingesetzt, weil sie – im Gegensatz zur Transformer Stage – auch eine „Behandlung“ der „unsichtbaren“ Spalten auf verschiedenen Arten ermöglicht. Dazu gehören:
- Umbenennung von Spalten
- Konvertierung von Datentypen
- Beibehaltung bestimmter Spalten
- Löschen bestimmter Spalten
- NULL-Handling
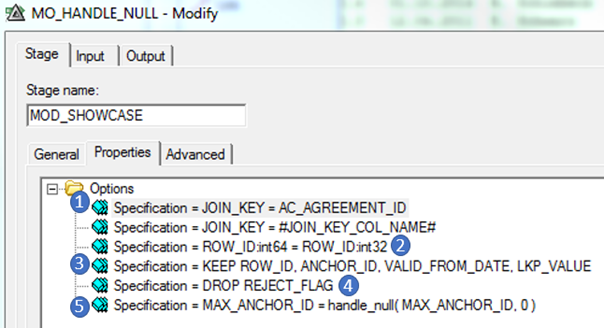
Darüber hinaus bietet die Modify Stage noch viele weitere Möglichkeiten, z.B. für Datentyp-Konvertierung (u.a. mit Lookup-Spalten) und NULL-Wert-Evaluierung.
Dazu siehe das Handbuch des Herstellers:
https://www.ibm.com/docs/en/iis/11.7?topic=tab-modify-stage-options-category
Generic Stage
Diese Stage ersetzt die herkömmlichen Stages (Sort, Lookup, Join etc.), wenn mehr Flexibilität gefordert ist.
Hier wird dann direkt der (native) osh-Befehl hinterlegt; Parameter machen den Aufruf flexibel. Ebenso wie die „normalen“ Stages kann auch die Generic Stage mehrere Input- und Output-Streams haben. Reference Streams werden nicht unterstützt. Beim Lookup muss dafür ein normaler Stream verwendet werden.
Das folgende Beispiel zeigt einen generischen Left-Outer-Join über eine parametrisierte Join-Key Spalte.
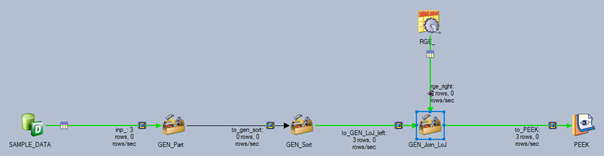
„GEN_Part“ zwecks Durchführung einer Hash-Partitionierung:
Operator = hash -key #JOIN_KEY#
„GEN_SORT“ zwecks Durchführung einer Sortierung nach Join-Key aufsteigend:
Operator = tsort -key #JOIN_KEY# -asc -nonStable
„GEN_Join_LoJ“ zwecks Durchführung eines Left-Outer-Join:
Operator = leftouterjoin -key #JOIN_KEY#
Alternativ zum Left-Outer-Join könnte man einen generischen Lookup verwenden:
Operator = lookup -table -key #JOIN_KEY# -ifNotFound continue
Tipp:
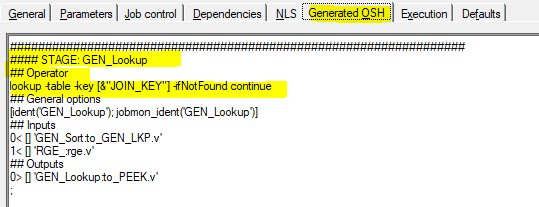
Den nativen osh-Befehl hat man gerade am Anfang nicht immer auswendig parat. Daher empfiehlt es sich, die ETL-Logik zunächst mit den herkömmlichen Stages zu implementieren. Ist der Job dann kompiliert, kann man in den Job Properties im Reiter „Generated OSH“ nach den nativen Befehlen suchen, um diese dann in der Generic Stage zu verwenden.
Mit dem hier beschriebenem Grundlagen-Know-how zur generischen Entwicklung lassen sich in DataStage sehr dynamische und flexible Lösungen erarbeiten. Diese können sowohl eine metadaten-gesteuerte Beladung von Tabellen („Generic Table Loader“) umfassen als auch eine einheitliche Berechnung komplexer Kennzahlen und Kennzeichen mittels Shared Container beinhalten.


