
Verfasst von: Patrick Wong, IT-Consultant
Dazu setzt das Tool auf parallele Verarbeitung, welche es u.a. durch die sog. Partitionierung erreicht. Dabei wird die Datenmenge eines Datenstroms (bzw. Link) zur Laufzeit auf 1 bis n Sub-Datenströme verteilt. Infolgedessen wird der ETL-Prozess beschleunigt, da diese Partitionen gleichzeitig im parallelen Framework ausgeführt werden.
Daher ist es für jeden ETL-Entwickler wichtig, die richtigen Partitionierungseinstellungen im Job zu treffen. Zudem benötigen einige Stages (wie z.B. die Join Stage oder die Change Capture Stage) eine korrekte Sortierung auf den Input-Links. Andernfalls brechen Jobs ab oder es werden gar falsche Ergebnisse produziert.
Im Folgenden wird anhand verschiedener Szenarien gezeigt, welche Auswirkungen falsches Sortieren & Partitionieren haben kann. Aber es werden auch Empfehlungen für den evtl. noch unerfahrenen Entwickler ausgesprochen, wie man es richtig macht.
In den Beispiel-Jobs werden folgende Tabellen verwendet:
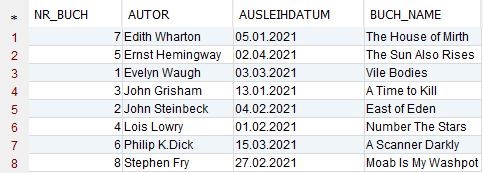
BUECHER:
AUSLEIHER:
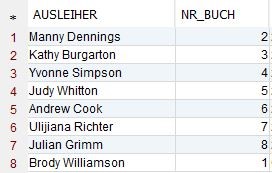
Die Datensätze sind so konstruiert, dass es zu jedem Eintrag in der Tabelle BUECHER einen entsprechenden Eintrag in der Tabelle AUSLEIHER gibt. Die Verknüpfung wird dabei über die Spalte NR_BUCH hergestellt.
Szenario 1: Inner Join bei 1node-Verarbeitung (d.h. ohne Parallelität)
Die beiden Beispiel-Tabellen werden hier per inner join über die Spalte BUCH_NR miteinander verknüpft. Partitionierung spielt keine Rolle, da der Job sequenzieller Art ist (sichtbar durch fehlende Partitionierungssymbole). Auch werden in diesem Szenario keine Sortierungen auf den beiden Input-Links durchgeführt.
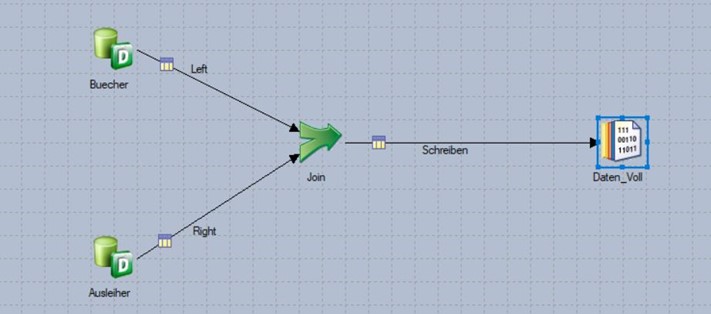
Unter diesen Bedingungen bricht der Job zur Laufzeit ab.
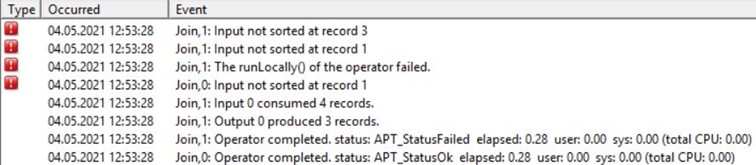
Beide Input-Ströme in die Join-Stage müssen zwingend nach dem Join-Key sortiert sein!
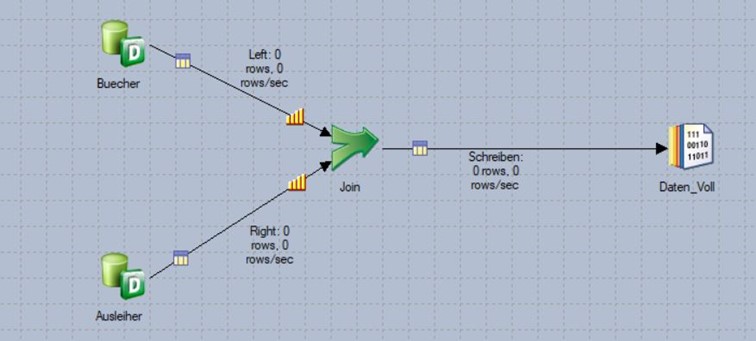
Dann läuft der Job fehlerfrei durch und die Ergebnismenge wird korrekt ermittelt.

Szenario 2a: INNER JOIN bei 2node-Verarbeitung (mit unterschiedlichen Partitionierungsmethoden)
In diesem Szenario werden die beiden Input-Ströme zwar nach dem Join-Key sortiert, aber unterschiedlich partitioniert (links nach „Round robin“, rechts nach „Modulus“).
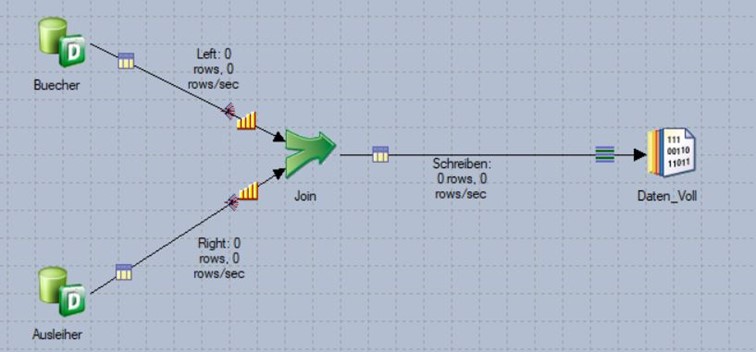
Der Job läuft zwar jetzt fehlerfrei durch, da beide Datenströme korrekt sortiert sind. Aufgrund der unterschiedlichen Partitionierungen können aber zu einigen Büchern keine Datenstände aus der Tabelle AUSLEIHER bestimmt werden. Beim Inner-Join erhält man in diesem Szenario daher nur Teilergebnisse:
Partition 0:
Partition 1:
Szenario 2b: LEFT JOIN bei 2node-Verarbeitung (mit unterschiedlichen Partitionierungsmethoden)
Stellt man in Szenario 2a auf einen Left Join um, weist die Ergebnismenge zwar alle Bücher aus, die Ergebnisse sind aber trotzdem falsch, weil (vorhandene) Informationen zum Ausleiher fehlen.
Partition 0:

Partition 1:

Der Grund dafür ist nachvollziehbar, wenn man sich die Ergebnisse der beiden unterschiedlichen Partitionierungsmethoden auf den Datenströmen anschaut:
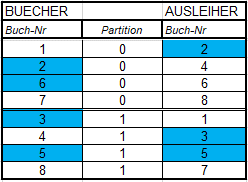
Da die linke Seite (BUECHER) nach „Round Robin“ und die rechte Seite („AUSLEIHER“) nach „Modulus“ partitioniert sind, landen die Datensätze in unterschiedlichen Partitionen und der Join liefert nur teilweise die richtigen Ergebnisse (blaue Kästchen).
Es gibt nun mehrere mögliche Lösungen. Die erste Lösung besteht darin, beide Strömungen mit Modulus zu partitionieren und nach NR_BUCH aufsteigend zu sortieren:


Oder es werden beide Datenströme nach NR_BUCH nach „Hash“ partitioniert und aufsteigend sortiert. Der Job liefert auch hier die richtigen Ergebnisse:


Wenn wir darauf bestünden, eine Round-Robin-Partitionierung für die BUECHER zu verwenden, müssten die AUSLEIHER nach „Entire“ partitioniert werden, um ein korrektes Ergebnis zu bekommen.


Wenn die Entire-Partitionierung benutzt wird, muss man beachten, dass die Datenmenge nicht zu groß ist. Ansonsten kann es zu Leistungsproblemen kommen, da bei „Entire“ alle Datensätze (redundant) in alle Partitionen dupliziert werden. Mit der Entire-Partitionierung zu arbeiten, kann gefährlich sein. Insofern, dass man z.B. aus Versehen den Hauptstrom (in diesem Fall die BUECHER) nach „Entire“ partitioniert. Dadurch würden zwangsläufig Duplikate erzeugt und das Ergebnis wäre falsch.
Zusätzliche Lösungsmöglichkeit: Auf eigene, explizite Partitionierung & Sortierung verzichten („Auto“) und es der bei den Standard-Einstellungen #$APT_NO_SORT_INSERTION# = False und #$APT_NO_PART_INSERTION# = False belassen und noch dazu den Parameter #$APT_SORT_INSERTION_CHECK_ONLY$# = False setzen.

Die Umgebungsparameter #$APT_NO_SORT_INSERTION# = False und #$APT_NO_PART_INSERTION# = False erlauben, dass Datastage eine Sortierung bzw. Partitionierung hinzufügt, wenn es das Tool für erforderlich hält.
Wie bereits oben beschrieben, bricht ein Job immer ab, wenn die Datenströme vor dem Join nicht sortiert sind. Daher muss für dieses Lösungsszenario noch der Parameter #$APT_SORT_INSERTION_CHECK_ONLY$# = False gesetzt werden, damit der Job ohne Sortierungswarnung weiterlaufen kann.
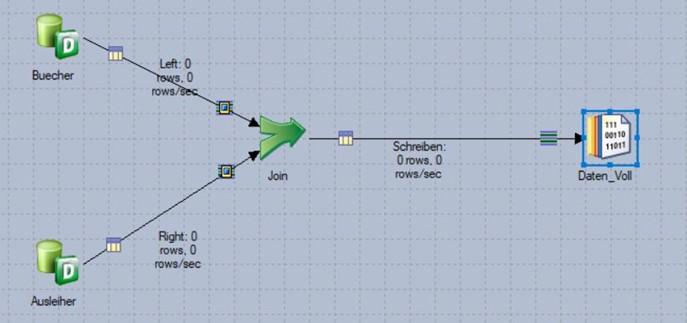


Der Ansatz, das Einfügen einer Sortierung und Partitionierung DataStage zu überlassen, kann im Zweifel – gerade für unerfahrene Entwickler – empfehlenswert sein gemäß dem Motto: „Besser alles auf ‚Auto‘ lassen, statt falsch zu partitionieren/sortieren und dadurch falsche Ergebnisse zu bekommen.“.
Fazit
Das parallele Framework macht InfoSphere DataStage zu einem hoch-performanten ETL-Werkzeug. Allerdings ist bei Partitionierung & Sortierung Vorsicht bzw. Gründlichkeit geboten, da es ansonsten zu fehlerhaften bzw. unvollständigen Daten kommen kann.
Dieser Beitrag soll dazu noch einmal Bewusstsein schaffen.


